")
Optical Mark Recognition (OMR) ist eine Technik zur computergestützten Erkennung von Markierungen auf Papier, ähnlich der Texterkennung (Optical Character Recognition oder OCR).
OMR wird häufig zur automatischen Auswertung von händisch – etwa durch Ankreuzen von vorgedruckten Felden – ausgefüllten Formularen wie zum Beispiel Multiple-Choice-Tests oder Wahlzetteln verwendet.
Der IPA-Server, Bestandteil der IPA-Suite, unterstützt nun die Optical Mark Recognition.
(14.06.2022) Optical Mark Recognition (OMR)
Das seit heute verfügbare Release 8.1.2.4 der IPA-Suite enthält Optical Mark Recognition (OMR). Die Technologie ist integraler Bestandteil des IPA-Server. Alle Kunden mit aktiver IPA-Suite Lizenz und IPA-Server Option können die neue Funktionalität ohne Aufpreis nutzen.
Für Neukunden ist ab sofort die Optical Mark Recognition in der IPA-Suite Lizenz enthalten. Voraussetzung ist lediglich die lizenzierte Option IPA-Server.
Wie generell beim IPA-Server ist die Lizenz vollumfänglich. Das bedeutet für den Kunden, er kann ohne weitere Kosten beliebig viele Dokumente verarbeiten und beliebig viele Scanner dafür nutzen.
Einfache Erstellung von OMR-Templates
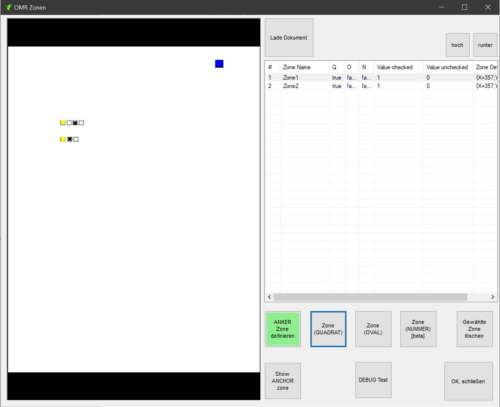
Die Erstellung eines OMR-Template, also einer Vorlage zur maschinellen Erkennung der Ankreuzfelder, ist mit dem IPA-Server besonders einfach:
- Scannen Sie eine Mustervorlage ein und laden Sie das Vorlage-Dokument im IPA-Server OMR-Designer
- Erstellen Sie einen Anker (siehe unten So wählen Sie den richtigen Anker)
- Ziehen Sie mit der Maus ein Feld über das Ankreuzfeld
- Geben Sie dem Feld einen Namen
- Setzen Sie den Wert für angekreuzt und nicht angekreuzt
- Wiederholen Sie die Schritte 3-5 für beliebig viele Ankreuzfelder
- Schließen Sie mit dem Button „OK, schließen“ den OMR-Designer und speichern Sie die Prozess-Konfiguration

Direkter Export in eine Excel-Datei
Scannen Sie nun Ihre händisch ausgefüllten Formulare ein. Der IPA-Server wertet die Ankreuzfelder aus und exportiert die Ergebnisse aller Formulare in eine Excel-Datei. Der Prozess passiert vollautomatisch.
Zusätzliche können Sie, z.B. durch Barcodes auf den Dokumenten, beliebige Zusatzinformationen mitgeben. So könnten Sie zum Beispiel die Umfragedaten in verschiedene Excel-Dateien exportieren, ohne vorher die Papierstapel zu sortieren.
Hintergrundwissen: Was ist Optical Mark Recognition (OMR)
Optical Mark Recognition (auch optisches Markierungslesen oder OMR genannt) ist der Prozess, bei dem wir Hardware, Software oder beides verwenden, um das von Menschen markierte Ausfüllen von Multiple-Choice-Fragen, Fragebögen mit richtigen oder falschen Feldern und allen Arten von Dokumentformularen zu erfassen.
Diese Arten von „Felder“, die wir OMR-Zonen nennen, kommen in fast jedem Formular vor, sei es bei einer Umfrage, bei der Sie z.B. Ihr Geschlecht angeben müssen und ob Sie berufstätig sind oder nicht, oder bei Multiple-Choice-Prüfungen, bei denen die OMR-Zonen die dominierende und wichtigste Art von Daten auf dem Formular sind.
Mit dem IPA-Server können Sie diese Dokumente scannen und ein System einrichten, das Ihnen schnell und genau mitteilt, ob jede OMR-Zone ausgefüllt ist oder nicht.
Komponenten eines OME-Systems
Jedes OMR-System besteht unabhängig von der Art des zu verarbeitenden Dokuments aus zwei Hauptkomponenten:
- Vorlage:
Dies ist normalerweise ein nicht ausgefülltes Dokument, in dem Sie den Speicherort der Daten angeben, die Sie extrahieren möchten. Diese „Daten“ sind in zwei Teile aufgeteilt:- Anker: Ein Logo, ein schwarzes Rechteck oder ein festes Objekt am Rand des Dokuments, von dem wir wissen, dass es in jedem ausgefüllten Formular vorkommt. Dies wird verwendet, um die Verschiebung gescannter ausgefüllter Formulare zu messen, aber dazu später mehr.
- OMR-Zonen: Das sind die Orte der Zonen, die von Menschen ausgefüllt werden müssen.
IPA-Server verwendet Rechtecke, die diese Felder umgeben, um ihre Position für den Erkennungsalgorithmus anzugeben.
- Gescannte Formulare:
Dies sind die gleichen Formulare wie die Vorlage, jedoch mit den von Menschen markierten Daten darauf.
Im Grunde genommen handelt es sich dabei um die Dokumente, aus denen wir die Informationen extrahieren möchten.
Der IPA-Server löst die gängigen Probleme anderer OMR-Systeme
In OMR-Systemen gibt es drei häufig zu sehende Fehlerquellen, die in der Produktion zu Problemen führen können:
- Verschiebungen durch Scannen:
Das wichtigste Problem. Die Positionen der OMR-Zonen im gescannten ausgefüllten Dokument sind niemals die gleichen wie die im Vorlagendokument angegebenen Positionen. Wieso ist das so?
Es gibt zwei Hauptgründe für dieses Phänomen:- Die Position des Dokuments im Scanner ist nie genau die gleiche wie die Position des Vorlagendokuments im Scanner. Dies ist einfach nur eine Tatsache des menschlichen Lebens, wo es schwierig ist, die Ausrichtung zu 100% korrekt zu halten.
- Dehnung entlang beider Achsen aufgrund des Einzugsmechanismus im automatischen Dokumenteneinzug des Scanners, falls dieser verwendet wird.
- Niedrige Auflösung der Bilder:
Niedrig aufgelöste Bilder, mit 150 dpi und weniger. Sie wirken sich auf die Bildqualität und damit auf die Qualität der OMR-Zonen und der darin enthaltenen Inhalte aus. - Kleine Felder:
Wenn die OMR-Zonen zu klein sind, hängt der Entscheidungsprozess in vielen Fällen von nur wenigen Pixeln ab, wodurch die Daten, die dem Erkennungsalgorithmus zur Verfügung stehen, zu klein werden, um eine genaue Entscheidung zu treffen, und die Fehlergrenzen größer werden.
Lösung Problem 1: Anker-Zone definieren und Verschiebung automatisch korrigieren
Der IPA-Server hat eine spezielle Technologie mit dem Namen „Anchoring Engine“, die Ihnen hilft, die Verschiebungen der Vorlage beim Scannen zu analysieren und die Platzierung der OMR-Zonen automatisch zu korrigieren.
Die „Anchoring Engine“ Technologie erkennt, unabhängig von der Kopie oder dem Scan, den definierten Anker durch die Analyse der Pixel des Bildes und berechnet in Abhängigkeit vom Anker die Positionen der OMR-Zonen.
Wenn der IPA-Server im ausgefüllten Dokument nach dem „Anker“ sucht, ihn findet und seinen Standort analysiert, so kann der neue Standort mit dem Standort im Vorlagendokument verglichen werden.
Der Unterschied zwischen den beiden Positionen in der X- und Y-Achse ist die Verschiebung. Der IPA-Server wendet diese Verschiebung auf die im Vorlagendokument angegebenen OMR-Zonen an und findet so die richtigen Positionen der OMR-Zonen.
Zu geringe Auflösung der Scans und zu kleine OMR-Zonen
Die beiden anderen Probleme können während des Formularentwurfs leicht behoben werden, indem mit 200-300 DPI gescannt und die OMR-Felder groß genug gemacht werden, um mehr als ein paar Pixel darin zu enthalten. Zudem können im IPA-Server zahlreiche Bildverbesserungsoptionen und -Technologien dabei helfen, die gescannten Vorlagen in der Bildqualität deutlich zu verbessern.
Comments are closed